- LineageOS: sideload connection failed: no devices found- 14.09.24
- Prestashop - 1-Click Upgrade findet kein Update- 03.01.24
- Prestashop: Paypal Modul wirft nach Update Fehler- 16.11.23
- Shopware - Google Feed- 10.01.23
- TYPO3: Redirects auf 301- 10.03.22
- PrestaShop: Herr, Frau, Divers- 03.02.22
- Plesk, externer Maildienstleister, unzustellbar- 17.06.21
Der Googlebot kann nicht auf CSS- und JS-Dateien zugreifen
Google hatte schon im Oktober letzten Jahres darauf hingewiesen, dass der Googlebot neben dem reinen HTML-Code auch CSS- und Javascript-Dateien beim Rendern analysierter Webseiten nutzt. In nicht wenigen Fällen werden jedoch genau diese Dateien gezielt - teils gewollt, teils aus Unwissenheit, teils aus historischen Gründen - durch Einträge in der robots.txt blockiert.
Wie gewohnt hat Google den Seitenbetreibern reichlich Zeit für Änderungen gegeben, doch heute trudelten die ersten Benachrichtigungen über die Webmastertool - jetzt ja Google Search Console genannt - ein:
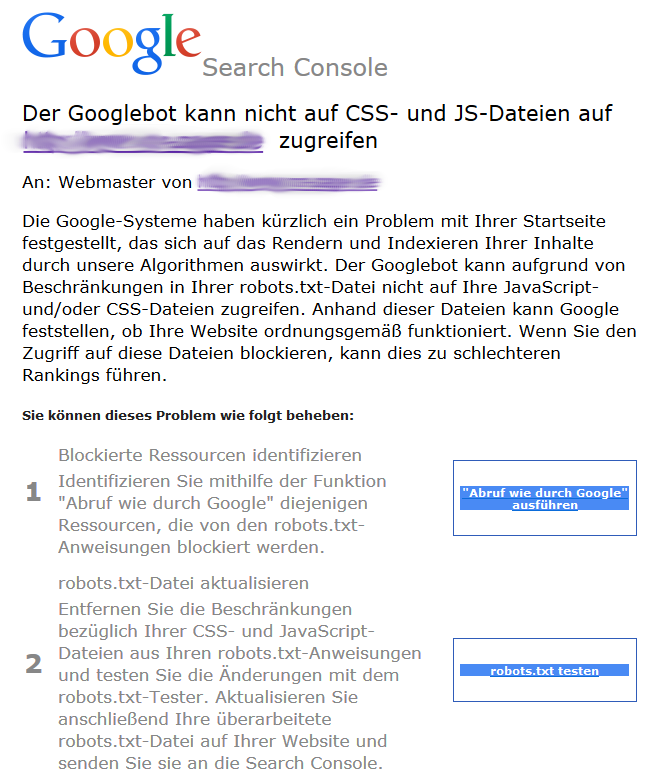
Konsequenzen für das Ranking?
Der Suchmaschinenriese nimmt in der oben zu sehenden Nachricht kein Blatt vor dem Mund und macht deutlich, dass ein verweigerter Zugriff zu einem verschlechterten Ranking führen kann! Es ist also höchste Zeit, aktiv zu werden.
Die notwendigen Änderungen sollten sich in den meisten Fällen auf die Löschung einer oder mehrerer Zeilen in der robots.txt beschränken. Google schlägt zur Prüfung und Identifikation der Problemzeilen das Tool "Abruf wie durch Google" vor. Die Frage stellt sich aber, ob nicht folgender Weg schneller ist:
- Im Quellcode die Pfade zu den CSS- und Javascript-Dateien herausfinden
- Prüfen, ob diese in der robots.txt vorkommen
- ... wenn ja, entfernen
Wer TYPO3 nutzt und im Quellcode viele einzelne Aufrufe von CSS- und Scriptdateien findet, dem sei die automatische Komprimierung und Zusammenfassung ans Herz gelegt.
Kommentare (0)
Keine Kommentare vorhanden